IBM SPSS Data Preparation
Improve Data Preparation for More Accurate Results
- Overview
- Features and Benefits
IBM® SPSS® Data Preparation gives analysts advanced techniques to streamline the data preparation stage of the analytical process. IBM SPSS Statistics Base, IBM SPSS Data Preparation provides specialized techniques to prepare your data for more accurate analyses and results.
With IBM SPSS Data Preparation, you can:
- Quickly identify suspicious or invalid cases, variables and data values
- View patterns of missing data
- Summarize variable distributions
- Optimally bin nominal data
- More accurately prepare your data for analysis
- Use Automated Data Preparation (ADP) to detect and correct quality errors and impute missing values in one efficient step
- Get recommendations and visualizations to help you determine which data to use

Expand your Data Preparation Techniques with IBM SPSS Data Preparation
Use the specialized data preparation techniques in IBM SPSS Data Preparation to facilitate data preparation in the analytical process. IBM SPSS Data Preparation easily plugs into IBM SPSS Statistics Base so you can seamlessly work in the IBM SPSS environment.
Perform Data Checks
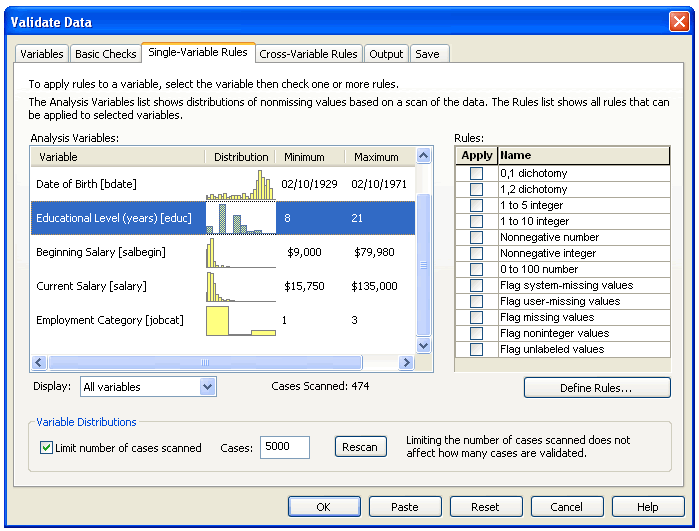
Data validation has typically been a manual process. You might run a frequency on your data, print the frequencies, circle what needs to be fixed and check for case IDs. This approach is time consuming and prone to errors. And since every analyst in your organization could use a slightly different method, maintaining consistency from project to project may be a challenge.
To eliminate manual checks, use the IBM SPSS Data Preparation Validate Data procedure. This enables you to apply rules to perform data checks based on each variable's measure level (whether categorical or continuous).
For example, if you're analyzing data that has variables on a five-point Likert scale, use the Validate Data procedure to apply a rule for five-point scales and flag all cases that have values outside of the 1-5 range. You can receive reports of invalid cases as well as summaries of rule violations and the number of cases affected. You can specify validation rules for individual variables (such as range checks) and cross-variable checks (for example, "retired 30 year-olds").
With this knowledge you can determine data validity and remove or correct suspicious cases at your discretion before analysis.
Quickly Find Multivariate Outliers
Prevent outliers from skewing analyses when you use the IBM SPSS Data Preparation Anomaly Detection procedure. This searches for unusual cases based upon deviations from similar cases, and gives reasons for such deviations. You can flag outliers by creating a new variable. Once you have identified unusual cases, you can further examine them and determine if they should be included in your analyses.
Pre-process Data before Model Building
In order to use algorithms that are designed for nominal attributes (such as Naïve Bayes and logit models), you must bin your scale variables before model building. If scale variables aren't binned, algorithms such as multinomial logistic regression will take an extremely long time to process or they might not converge. This is especially true if you have a large dataset. In addition, the results you receive may be difficult to read or interpret.
IBM SPSS Data Preparation Optimal Binning, however, enables you to determine cutpoints to help you reach the best possible outcome for algorithms designed for nominal attributes.
With this procedure, you can select from three types of binning for pre processing data:
- Unsupervised -- create bins with equal counts
- Supervised -- take the target variable into account to determine cutpoints. This method is more accurate than unsupervised; however, it is also more computationally intensive.
- Hybrid approach -- combines the unsupervised and supervised approaches. This method is particularly useful if you have a large number of distinct values.